
The Agentic Engineering Gap
Why traditional AI, Machine Learning, and Data Science curricula are no longer enough - and what college leadership should be thinking about now

A research brief for college principals, deans, HoDs, and faculty in engineering, technology, and management institutions.

TL;DR
The argument in seven points, for readers short on time.
AI has moved through three eras in fifteen years. Predictive AI (custom models, 2010-2022) → Generative AI (foundation models, 2022-2024) → Agentic AI (autonomous systems on frontier models, 2024-now). Each era is cumulative, not replacement. Most college curricula are calibrated to Era 1.
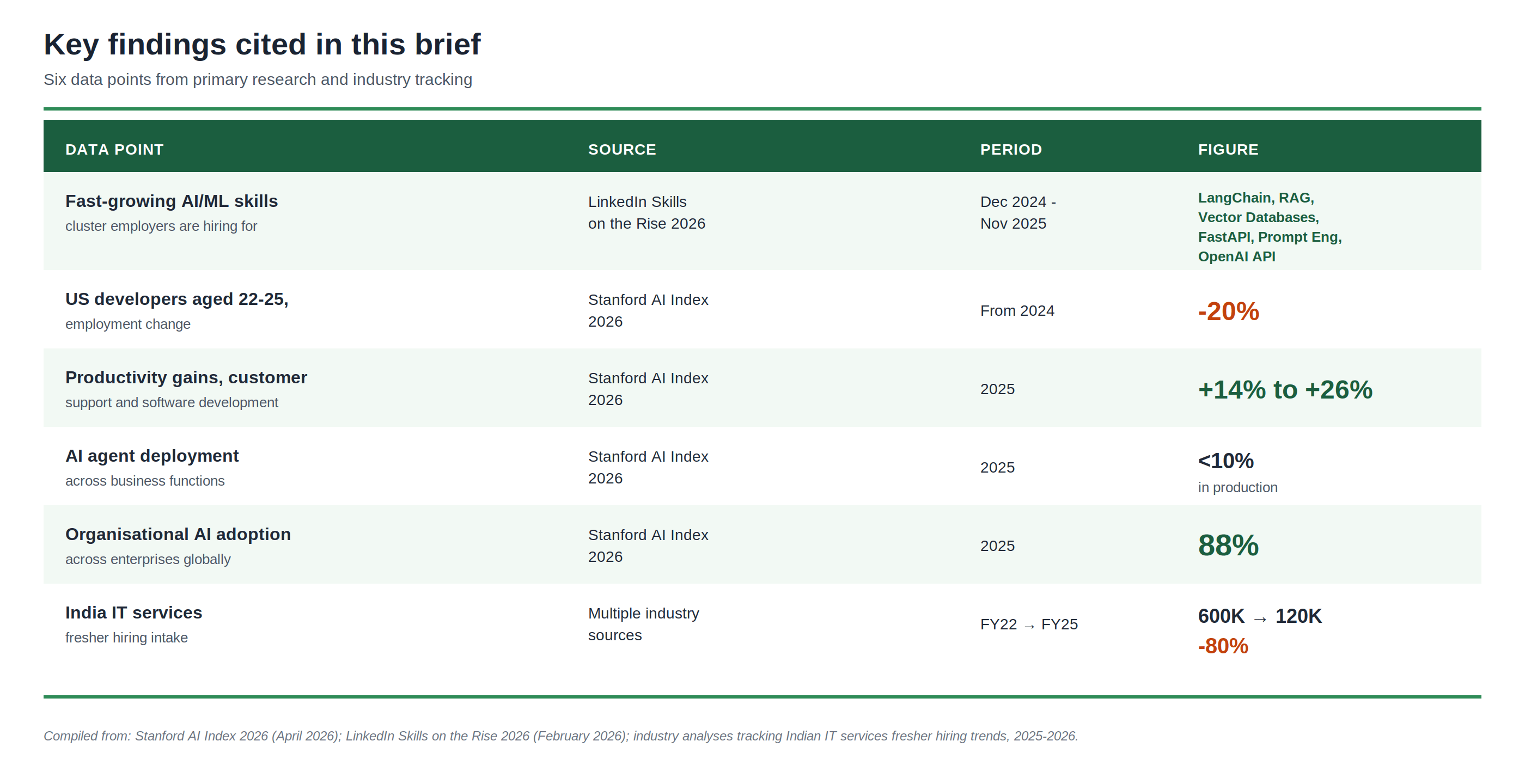
The hottest hiring skills in 2026 are agentic engineering skills, not classical ML. LinkedIn’s Skills on the Rise 2026 names LangChain, RAG, Vector Databases, FastAPI, Prompt Engineering, and OpenAI API among the fastest-growing AI/ML skills employers are hiring for. Most of these do not appear in standard college AI/ML or Data Science curricula.
Enterprise adoption is broad but agent deployment is still early. Stanford AI Index 2026 reports 88% organisational AI adoption, but AI agent deployment remains in single digits across business functions. The hiring is rising faster than the deployments - meaning colleges that act in the next 12-18 months will be supplying a market that is just beginning to scale.
Indian IT services fresher hiring fell 80% in three years. From approximately 600,000 in FY22 to 120,000 in FY25. This is structural, not cyclical. The work that filled a junior employee’s first year is now being done by AI as a first pass.
AI engineering compensation is now among the highest in technology. US AI engineer national average is $173,482 (Glassdoor 2026); Indian Generative AI Engineer salaries reach ₹20-45 LPA at mid-level, with Agentic AI Engineer salaries climbing to ₹80+ LPA. Cost arbitrage is driving global companies to hire Indian AI engineers at scale.
Recruiters are screening for portfolio, not transcript. Anthropic’s hiring page states explicitly that PhDs are not required and that approximately 50% of their technical staff do not have PhDs. The published instruction to candidates: “If you have done interesting independent research, written an insightful blog post, or made substantial contributions to open-source software, put that at the TOP of your resume.”
The right response is augmentation, not replacement. Strong AI/ML and Data Science foundations are valuable. The question for college leadership is what gets layered on top - and how fast.
For who this is, and what it is not. This brief is written for college decision-makers thinking about AI curriculum strategy through 2026-27. It is not a call to abandon existing programmes. It is an argument that the engineering layer above foundation models is now where industry is hiring, and that augmenting AI/ML and Data Science programmes with agentic engineering content is the lowest-cost, highest-leverage action available to college leadership in the next 12-18 months.
Most Indian engineering, technology, and management colleges have, in the last five years, made meaningful investments in Artificial Intelligence education. AI/Machine Learning specialisations, Data Science programmes, dedicated AI&DS departments - these are now routine across the country’s better institutions. The investments have been substantial. The programmes are functional. The faculty have been trained.
This brief is not an argument against any of that.
It is an argument that those investments, valuable as they are, have been overtaken by a shift in industry that most curricula have not yet absorbed. The work that AI engineers are now being hired to do is structurally different from the work that traditional AI/ML/Data Science curricula prepare students for. The gap is widening, the hiring data is becoming visible, and the next two placement cycles will likely be the moment when colleges that have not adapted will see their placement reputation - quietly, without public announcement - begin to slip.
The thesis of this brief is straightforward: AI/ML and Data Science curricula were designed for an era when the central work was building custom models. The industry has now decisively shifted to building agentic systems on top of foundation models. The two require different skill stacks. Most college curricula have not yet caught up.
What follows is an evidence-based examination of where this gap is showing up, what is driving it, and what college leadership might productively consider in response. The piece is long because the audience asked for is one that reads carefully. The data is dense because the claim is one that deserves scrutiny. The framing is “augmentation, not replacement” because the existing programmes are valuable and the gap is in what sits on top.
1. Three eras of AI: understanding what has changed
To understand why curricula need to evolve, it helps to step back and look at how the AI domain itself has changed over the last fifteen years. The shift is not a single moment - it is a progression through three distinct eras, each defined by what the AI does, what the engineering work looks like, and what enterprises can practically build.
1.1 Era 1 - Predictive AI (roughly 2010-2022)
In the first era, AI meant building custom models that could predict, classify, or recommend. A retailer trained a model to forecast demand for the next quarter. A bank built a fraud detection classifier. An e-commerce platform built a recommendation engine. Each model was specific to one use case, trained on the company’s own labelled data, and required substantial machine learning expertise to build, evaluate, and deploy.
The engineering work in this era was largely about the model itself. Data scientists collected and cleaned data. Machine learning engineers trained, tuned, and validated models. MLOps engineers built the infrastructure to deploy and monitor them in production. The toolchain was Python with scikit-learn, TensorFlow, PyTorch, XGBoost. The capability of the AI system was bounded by the size and quality of the labelled training data and the engineering effort invested in feature engineering and model tuning.
This is the era that most current college AI/ML and Data Science curricula were designed for. The skills taught - statistical foundations, classical machine learning, deep learning frameworks, model training and evaluation - are precisely the skills this era required. The curricula are not wrong. They are correctly calibrated to a specific era of AI work.
1.2 Era 2 - Generative AI (2022-2024)
The second era began when generative foundation models reached commercial-grade capability. The launch of ChatGPT in November 2022 was the public turning point, but the underlying shift had been building for years through advances in transformer architectures, training compute, and dataset scale.
What changed fundamentally was the relationship between the model and the application. In Era 1, you built a specific model for a specific task. In Era 2, you used a general-purpose foundation model and prompted it to perform tasks. The same model that could write a poem could also summarise a legal document, draft an email, or explain a piece of code. The engineering work shifted from training the model to working with it - prompt engineering, retrieval-augmented generation (RAG), structured output handling, context management.
This was the era when “AI” became something every knowledge worker could use directly, not just something embedded inside enterprise software. By the time Stanford’s AI Index 2026 measured it, generative AI had reached 53% population-level adoption within three years of ChatGPT’s launch - faster than the personal computer or the internet.
For colleges, Era 2 introduced new skills that were largely absent from existing curricula: prompt engineering, working with LLM APIs, vector databases for retrieval, embeddings for semantic search. A few colleges added these as elective topics. Most did not.
1.3 Era 3 - Agentic AI (2024 to now)
The third era began when foundation models became capable enough to plan, reason, and execute multi-step workflows autonomously, using external tools, with memory across long sessions. This is the era we are in now.
In Era 2, you asked an AI to write something for you, and it wrote it. In Era 3, you give an AI a goal, and it figures out the steps, calls the tools it needs, manages its own memory, evaluates its own outputs, recovers from errors, and produces a finished result. The shift is from “AI as a tool you operate” to “AI as an autonomous worker you direct.”
The engineering work in this era is fundamentally different from either Era 1 or Era 2:
Agent design - how to structure prompts and tool access so the agent can plan effectively
Tool integration - giving agents access to APIs, code execution, file systems, databases
Multi-agent orchestration - building systems where specialised agents collaborate on complex tasks
Memory and context management - maintaining state across long, multi-step workflows
Evaluation harnesses - testing agent behaviour systematically, catching silent regressions
Production engineering - cost attribution, observability, graceful failure handling, guardrails
None of these skills appear in standard AI/ML or Data Science curricula. They have emerged in the last 24-36 months, primarily within frontier labs (Anthropic, OpenAI, Google DeepMind) and AI-first startups (Cognition, Adept, Replit, Cursor, and others). The graduates who can do this work were either trained directly at these companies or built the skills independently through open-source projects and self-directed learning.
This is the gap. Era 1 skills are taught well. Era 2 skills are taught patchily. Era 3 skills are largely not taught at all. And Era 3 is where the hiring is.
1.4 What each era includes from the one before
Critically, these eras are cumulative, not replacement. A modern agentic system still uses predictive models inside it - for example, a customer support agent might use a classification model to route tickets, a retrieval model to find relevant past cases, and a generative model to draft responses. The agentic layer composes these capabilities into autonomous workflows.
This is why “augmentation, not replacement” is the right framing for curriculum. Era 1 and Era 2 skills are not obsolete - they are the foundation. Era 3 skills sit on top of them. A graduate who knows the full stack - classical ML + foundation models + agentic engineering - is the most valuable hire of all. The graduate who stops at Era 1 or Era 2 is missing the layer where industry is now investing.
2. The job market inversion
2.1 The fastest-growing skills in 2026 are agentic engineering skills
LinkedIn’s 2026 Skills on the Rise report, published on February 24, 2026, identifies the fastest-growing skills professionals are adding to profiles and employers are actively hiring for, measured by year-on-year growth from December 2024 to November 2025. The top AI/ML skills cluster contains a specific list that maps almost exactly to the agentic engineering stack: Data Annotation, FastAPI, Google Gemini, LangChain, Model Training and Fine-Tuning, OpenAI API, Prompt Engineering, Retrieval-Augmented Generation (RAG), Vector Databases, and XGBoost. (Source: LinkedIn Economic Graph, Skills on the Rise 2026, February 24, 2026.)
LinkedIn’s own explanation of why this cluster is growing is worth quoting directly. The skills are growing, the report states, because “as AI adoption accelerates, so does the need for professionals with the technical expertise required to build, integrate and operationalize AI models and applications. That expertise includes connecting AI systems to company data, shaping model outputs through prompting and tuning and embedding AI into real-world products using APIs and infrastructure.”
Note what this list contains and what it does not. It contains LangChain, RAG, Vector Databases, FastAPI, Prompt Engineering, and OpenAI API - all of which are core to building production agentic systems on top of frontier foundation models. It contains XGBoost and Model Training/Fine-Tuning - the traditional ML side - but these sit alongside, not replacing, the agentic stack. The implication is unambiguous: the engineering layer above the foundation model is now where the fastest skill demand is concentrated, and it is concentrated in skills that most college curricula do not yet teach.
A second LinkedIn cluster worth noting is “Responsible AI for Business Leaders,” whose fast-growing skills include AI for Business, AI for Design, Data Governance, Responsible AI, and Tech-Enabled Business Transformation. The note for this cluster: “With the shift of AI from experimentation to application, organizations need leaders who can define where and how AI adds value.” This signals that demand is not only for engineers - it is also for leaders who understand what AI can and cannot do at the business process level. This is the process-level fluency we will return to in Section 4.
2.2 Agentic AI engineering skills are accelerating fastest in specific emerging economies
The Stanford AI Index 2026, published in April 2026 by the Stanford Institute for Human-Centered AI (HAI), notes in its top takeaways that AI engineering skills are accelerating fastest in the United Arab Emirates, Chile, and South Africa - emerging economies that have made aggressive AI policy and infrastructure commitments. (Source: Stanford HAI, AI Index Report 2026, April 2026, Top Takeaways #13.)
For Indian college leadership, this is a useful comparison point. The skill acceleration is happening in markets that are smaller and less mature than India in technology hiring overall, but more concentrated in their AI commitments. Indian colleges that produce agentic engineering talent at scale would be supplying a labour market where global demand is rising fastest in places like UAE - where, separately, the federal government announced in April 2025 a framework to deploy autonomous agentic AI across 50% of government sectors within two years.
2.3 Entry-level work is being automated; the productivity gains are real
The Stanford AI Index 2026 is sharp on the labour market implications of AI’s productivity effects. Its findings (Top Takeaways #9):
Productivity gains of 14% to 26% are documented in customer support and software development - the categories where AI’s measured impact is clearest
U.S. developers aged 22 to 25 saw employment fall nearly 20% from 2024, even as headcount for older developers continues to grow
The gains are “weaker or negative” in tasks requiring more judgment
The report adds a critical caveat that should be read carefully by any college leader thinking about AI hiring trends: “AI agent deployment remains in single digits across nearly all business functions.” Enterprises are still in early stages of deploying autonomous agents at scale. The hiring is happening because companies are building the talent base for the next phase, not because agents are already running most workflows. This is exactly the moment when curriculum changes have the most leverage - the talent demand is rising, the deployments are just beginning, and the colleges that produce the right graduates first will define the supply.
2.4 The Indian context: a structural compression that has already happened
Indian engineering and technology colleges should pay particular attention to one statistic. According to multiple industry analyses published in 2025-2026, the Indian IT services sector’s fresher hiring intake peaked at approximately 600,000 in FY22. By FY25, that number had dropped to approximately 120,000 - an 80% decline in three financial years. (Source: Multiple industry analyses including Business Today, Economic Times, and industry tracking reports, 2025-2026.)
FY26 hiring projections suggest only marginal recovery. This is not a cyclical downturn that will reverse when global demand picks up. Senior leaders at IT services firms have stated, publicly and privately, that the structural shift is permanent. The work that filled a junior employee’s first year of training - first-draft code, first-draft analysis, first-draft client communication - is now being done by AI as the first pass. The employee who gets hired now has to be the second draft.
For Indian colleges, this is the single most important data point in this brief. The largest fresher hiring programme in India’s history has structurally compressed by four-fifths in three years, and the reasons are tied directly to the AI capability shift documented in the Stanford AI Index.
3. Why this shift is happening: the foundation model effect
3.1 The economics of AI have inverted
Until approximately 2022, the standard playbook for an enterprise wanting to deploy AI was clear. Collect proprietary data. Train a custom model. Tune, evaluate, deploy. The model itself was the asset, and the engineering work was largely in producing the model.
That playbook has been broken by frontier foundation models. Models from Anthropic (Claude), OpenAI (GPT), Google (Gemini), and others have improved at a rate that makes custom model training uneconomic for the vast majority of enterprise use cases. The Stanford AI Index 2026 confirms a notable consequence: at the technical frontier, leading models are now nearly indistinguishable from one another. Open-weight models are more competitive than ever. The US-China model performance gap has effectively closed, with leading models trading the lead multiple times since early 2025. (Source: Stanford HAI, AI Index Report 2026, Introduction and Top Takeaways #2.)
The implication for engineering work has been profound. The asset is no longer the model. The asset is the agentic system built on top of the model - the orchestration, the tool integrations, the memory, the evaluation harnesses, the guardrails, the production deployment. The engineering layer above the foundation model is now where the value is created.
Even fine-tuning - the lighter version of custom model training - has become selective. Techniques like LoRA (Low-Rank Adaptation) allow targeted adaptation at a fraction of the cost of full training, and even these are deployed conservatively. The dominant pattern in enterprise AI in 2025-2026 is: use the frontier model as a platform; do the engineering work in the layer above it.
3.2 Enterprise adoption: AI has reached mass scale, agent deployments are still in early innings
The shift to AI as a mainstream tool is no longer in question. The Stanford AI Index 2026 documents that:
Organizational adoption of AI rose to 88% in 2025 (Top Takeaways #1)
Generative AI reached 53% population-level adoption within three years, faster than the personal computer or the internet (Top Takeaways #8)
U.S. private AI investment reached $285.9 billion in 2025, more than 23 times the $12.4 billion invested in China (Top Takeaways #7)
Global corporate AI investment more than doubled in 2025 (Introduction)
The estimated value of generative AI tools to U.S. consumers reached $172 billion annually by early 2026, with median value per user tripling between 2025 and 2026 (Top Takeaways #8)
These figures establish that AI adoption is now mass-scale across enterprises and consumers. The investment is committed, the user base is large, and the foundation models are reaching commodity-level capability.
However, when it comes specifically to autonomous AI agents in production, the Stanford AI Index 2026 provides an important corrective to the more bullish industry forecasts. Its finding (Top Takeaways #9): “AI agent deployment remains in single digits across nearly all business functions.”
This is a critical signal for college leadership. It tells you two things at once:
The hiring is rising faster than the deployments. Companies are building agentic engineering teams now to be ready for the production deployment wave that is just beginning. They are hiring ahead of deployment, not behind it.
The curriculum window is open, not closed. If autonomous agent deployment is still in single digits, then the colleges that produce agentic engineering talent in the next 18-24 months will be supplying a market that is just beginning to scale. Colleges that act after the deployment wave hits will be supplying a market where the talent pipeline has already been claimed by faster-moving institutions.
3.3 The productivity gains are real, but the deployments are more nuanced than headlines suggest
The Stanford AI Index 2026 documents (Top Takeaways #9) productivity gains of 14% to 26% in customer support and software development. These are the categories where AI’s measured impact is clearest.
Several enterprise deployments have been widely publicised, and they reveal a more nuanced picture than the headlines suggest. The honest version of this story is more useful for college leadership than the simpler “AI replaces workers” narrative.
Klarna’s customer service AI assistant (launched February 2024 in partnership with OpenAI) was the most-cited business deployment of agentic AI in 2024. Within thirty days, it had handled 2.3 million customer conversations - approximately two-thirds of all Klarna customer service chats - and was doing the equivalent work of 700 full-time agents. Klarna estimated $40 million per year in avoided hiring costs. By early 2025, however, Klarna began publicly walking back the AI-only approach. CEO Sebastian Siemiatkowski acknowledged that the company had “focused too much on efficiency and cost” and that customer satisfaction had dropped on complex cases. Klarna is now hiring human agents back, but in a hybrid model where AI handles routine queries and humans handle complex, nuanced, or emotionally sensitive cases. (Sources: OpenAI customer story 2024; Fast Company January 2026; Business Insider 2025.)
The Klarna case is the most important story in agentic AI deployment because it tells college leadership two truths simultaneously. The first truth: AI agents can genuinely automate large volumes of routine work at near-human quality, and the productivity gains are real and measurable. The second truth: judgement, empathy, and complex reasoning still require humans, and companies that over-automate will pay a quality cost. The graduates who succeed in this market are the ones who understand both - they can build the agentic systems that handle routine work and they can recognise where humans must remain in the loop. This is exactly the “judgement at the seam” skill that the curriculum gap section will return to.
Other widely publicised agentic deployments include:
Salesforce Agentforce (launched October 2024): customers including Wiley, ADP, and Workday report automating 60-85% of tier-1 customer service interactions and routine sales follow-ups
Oracle Miracle Agent (embedded in Fusion Cloud): enterprise customers report cutting invoice processing cycles by approximately 80%, with use cases extending across HR, supply chain, and procurement
SAP Joule (across SAP enterprise suite): autonomous task handling in operations, reporting, and procurement workflows
Microsoft Copilot agents (in Dynamics 365 and Microsoft 365): doubled active enterprise usage year-on-year by mid-2025, with specific agents for lead qualification, invoice reconciliation, and meeting summaries
Amazon’s AgentCore and Rufus: shopping assistant and developer agents handling marketplace tasks, e-commerce workflows, and supply chain operations
ServiceNow agentic workflows (with Anthropic partnership): IT service management and workflow automation
Thomson Reuters CoCounsel: legal research synthesis used by over one million legal professionals
eSentire: cybersecurity threat analysis tasks compressed from approximately 5 hours to approximately 7 minutes per case
L’Oreal: natural-language data querying deployed for tens of thousands of internal users
Wyndham Hotels: multi-agent systems for franchise operations and customer service
A McKinsey survey published in 2025 reported that 65% of organisations were regularly using generative AI in at least one business function, and that organisations with the most mature AI deployments - what McKinsey terms “high performers” - were three times more likely than peers to have begun deploying AI agents in production. PwC’s 2025 AI Agent Survey of 300 senior executives found 79% adoption of AI agents in some form, with 88% planning to increase AI budgets in the following 12 months specifically because of agentic capability development. (Sources: McKinsey & Company, The State of AI 2025, March 2025; PwC, AI Agent Survey, May 2025.)
The picture is consistent. Enterprises are committing budgets, building teams, and shipping agentic systems. The deployments are real and scaling. The Klarna nuance is critical: the wins are in routine work; the failures are where companies tried to remove humans from work that required judgement.
3.4 Government deployments: agentic AI at national scale
The shift is not confined to corporate enterprise. National governments have begun deploying agentic AI at scale.
The United Arab Emirates announced in April 2025 plans to deploy autonomous agentic AI across approximately 50% of government sectors, services, and operations within two years. The framework explicitly redesigns policies and processes around AI capability rather than retrofitting AI onto existing processes. The Stanford AI Index 2026 specifically notes that the UAE leads globally in AI engineering skill acceleration, alongside Chile and South Africa.
Singapore’s GovTech, in partnership with Google Cloud, deployed agentic AI on air-gapped cloud infrastructure for public services beginning in 2024 - reportedly the earliest large-scale government use of agentic AI in Asia. Singapore’s Smart Nation 2.0 strategy includes specific agent deployments such as VICA (a virtual intelligent chat assistant deployed across more than 60 government agencies), AISAY (a document-reading agent for unstructured data extraction and validation), and MAESTRO (a central AI/MLOps platform for scaling agent deployment).
The Stanford AI Index 2026 also notes that more than half of newly adopted national AI strategies in 2025 came from developing countries entering the policy landscape for the first time (Introduction). The investment commitment is global and growing.
The point of citing these is not to suggest Indian colleges should imitate UAE or Singaporean governance - it is to demonstrate that agentic AI is moving from experimental pilots toward national-scale infrastructure. The hiring market is responding.
SIDEBAR: Notable Agentic AI Systems in 2025-2026
A non-exhaustive list of agentic systems that have moved beyond demos into production use or wide public adoption. This is what “agentic AI” looks like in practice - not as a category, but as specific products that work today.
Personal and desktop agents
OpenClaw (open-source, viral throughout 2025): a personal agent framework that runs locally and can be messaged through WhatsApp, Telegram, and other apps to carry out tasks across applications. The viral success of OpenClaw triggered a wave of similar deployments across the industry; its creator Peter Steinberger was hired by OpenAI to lead personal agent development.
Anthropic Claude Computer Use (launched in beta October 2024, expanded March 2026): Claude can directly control a desktop computer, opening applications, navigating browsers, filling spreadsheets, and chaining multi-step workflows. Early adopters include Asana, Canva, Cognition, DoorDash, Replit, and The Browser Company.
Anthropic Claude Cowork (released early 2026): a “digital coworker” mode within the Claude desktop app, built for non-developer knowledge workers - researchers, analysts, operations teams, legal professionals - to autonomously execute multi-step tasks across files and applications.
Nvidia NemoClaw (launched 2025): enterprise version of the OpenClaw framework, positioned by Nvidia CEO Jensen Huang as “definitely the next ChatGPT.”
OpenAI Operator (launched January 2025): browser-based agent that completes tasks on the web on behalf of users - filling forms, making reservations, comparing products.
Software development agents
GitHub Copilot Workspace and Coding Agent: AI agents that take a GitHub issue, propose a plan, implement the code, run tests, and open a pull request for human review.
Cursor and Windsurf: AI-native code editors built around agentic coding assistance; both reached significant developer adoption in 2025.
Replit Agent: scaffolds entire applications from natural language descriptions; particularly popular with non-developer founders building MVPs.
Cognition’s Devin: an autonomous software engineering agent that completes coding tasks end-to-end, including debugging and testing.
Anthropic’s Claude Code: an agentic coding tool originally built for Anthropic’s internal use; widely adopted across the industry in 2025-2026 and now powering “almost all major agent loops” at Anthropic itself, according to the company’s January 2026 engineering post.
Customer service and enterprise operations agents
Klarna’s customer service agent (handled 2.3 million chats equivalent to 700 agents in early 2024; now in hybrid model after quality concerns - see Section 3.3 for the nuanced story)
Salesforce Agentforce (autonomous sales, service, and marketing agents inside Salesforce CRM)
Decagon, Sierra, and Intercom Fin: third-party agentic customer service platforms automating tier-1 support for hundreds of mid-market and enterprise companies
Beam.ai: transaction reconciliation agents reportedly achieving over 99% accuracy across enterprise finance and HR clients
Specialised vertical agents
Harvey (legal): contract analysis, legal research, and drafting agents deployed across major law firms including Allen & Overy
eSentire (cybersecurity): threat analysis agent compressing 5-hour tasks to 7 minutes
Thomson Reuters CoCounsel (legal): research synthesis used by over 1 million legal professionals
Clinical scribe agents (multiple vendors, Stanford AI Index 2026 reports up to 83% reduction in physician note-writing time across multiple hospital systems)
Sakana AI (Japan): autonomous AI research agents that conduct end-to-end scientific research, from hypothesis to paper
Google’s AI Co-Scientist: agentic system for biomedical research collaboration with human scientists
Government and public sector agents
Singapore VICA: virtual intelligent chat assistant deployed across 60+ government agencies
Singapore AISAY: document-reading agent for unstructured data extraction in government workflows
UAE federal agentic AI deployment: announced April 2025, targeting 50% of government sectors within two years
What this list tells you: Agentic AI is no longer experimental. It is shipping, scaling, and increasingly the way work gets done across every industry from law to medicine to government. The engineers who build these systems - and the graduates who will join the teams building the next ones - are the ones in highest demand.
4. The curriculum gap
This is the section where the analysis becomes uncomfortable for college leadership. The argument is not that existing AI/ML/Data Science curricula are wrong. They are not. The argument is that they are incomplete for the work the industry is now hiring for.
4.1 What standard AI/ML/Data Science curricula teach well
Most Indian engineering and technology colleges with AI/ML or Data Science programmes teach the following well:
Statistical foundations: linear algebra, probability theory, optimisation, multivariate calculus
Classical machine learning: regression, classification, clustering, ensemble methods, dimensionality reduction
The Python data science stack: NumPy, Pandas, scikit-learn, Matplotlib, Seaborn
Deep learning frameworks: TensorFlow and PyTorch for building neural networks
Model training and evaluation: training/validation/test splits, cross-validation, hyperparameter tuning, evaluation metrics (precision, recall, F1, AUC)
Data engineering basics: ETL, SQL, data cleaning, feature engineering
These are valuable, foundational, and correctly taught. The faculty effort that has gone into building these programmes is real and should not be discounted. The gap is not in what is taught - the gap is in what sits on top of these foundations that most curricula have not yet incorporated.
4.2 What standard curricula typically miss: the agentic engineering stack
The work that AI engineers are now being hired to do involves a set of skills that has emerged in the last 24-36 months and is largely absent from most college curricula. Industry job postings in 2025 routinely require some combination of the following:
Frontier-model agent design and engineering:
Composing prompts that produce reliable structured outputs
Managing context windows and token economics
Working with multiple foundation model providers (Claude, GPT, Gemini) and routing between them based on task characteristics
Understanding the tradeoffs between latency, cost, and capability across model tiers
Tool calling and external system integration:
Function calling and API integration patterns
Building agents that can invoke external tools (databases, search, code execution, file systems)
Handling tool failures gracefully
Designing tool schemas that are unambiguous to LLMs
Multi-agent orchestration:
Designing systems where multiple specialised agents collaborate
Manager-worker patterns, debate patterns, planning-execution separations
Communication protocols between agents
Handling conflicts and coordination failures
Memory and context management:
Maintaining state across long workflows
Vector databases for semantic memory (Pinecone, Weaviate, Chroma)
Retrieval-Augmented Generation (RAG) architectures
Context summarisation and compression strategies
Evaluation harnesses (evals):
Designing test suites for non-deterministic outputs
LLM-as-judge methodologies and their failure modes
Human-in-the-loop evaluation patterns
Detecting silent regressions when models or prompts change
Production engineering:
Cost attribution and budget management for API usage
Latency optimisation through caching, batching, and routing
Observability for probabilistic systems
Graceful degradation when models fail or hallucinate
Guardrails and safety:
Input validation and prompt injection defences
Output validation against business rules
Audit trails for regulated industries
Preventing runaway agent behaviour
This list is not exhaustive. It is a representative sample of what industry job postings now demand and what most college curricula do not yet provide.
4.3 Why the gap exists
Three structural reasons explain why most curricula have not yet closed this gap.
Curriculum review cycles are slower than AI capability cycles. Most Indian universities review and update curricula on a 3-5 year cycle. Foundation model capabilities have been changing on a 12-18 month cycle. By the time a new curriculum is approved, the capability landscape has moved twice.
Faculty have not had structured exposure to agentic engineering. Agentic engineering as a coherent discipline emerged in 2023-2024. Most AI/ML faculty completed their training before this period. The gap is not faculty capability - it is faculty exposure. Closing the gap requires structured faculty development, not just student training.
Hands-on agentic engineering requires teaching teams who have built production agents, not just taught about them. This is the harder problem. The patterns and judgement that matter most in agentic engineering - knowing when a multi-agent system will fail, how to design evaluations that actually catch regressions, how to debug a probabilistic pipeline - are learned through doing, not reading. Most college faculty have not had the opportunity to build production agentic systems.
4.4 The hybrid skills problem
A second-order issue compounds the curriculum gap. Industry job postings for “AI Engineer” now routinely demand a combination of skills that no single traditional curriculum produces:
Machine learning fundamentals
Software engineering and backend development
Data engineering (ETL, pipelines, databases)
Cloud infrastructure and DevOps
Frontend development for agent interfaces
Generative AI specialisation
This is an impossible-looking combination. It filters out most graduates from traditional CSE, AI/ML, or Data Science programmes - not because those programmes are deficient, but because they are specialised. The graduates who succeed in current AI engineering job markets are typically those who have, on their own initiative outside the curriculum, built deployed agentic systems. They have a GitHub portfolio. They have shipped something. They can speak to production failures.
The implication for curriculum design is significant: producing students who can pass an AI engineering interview today requires giving them a project portfolio, not just a transcript.
What this means for placements
The argument above is abstract. This section makes it concrete in the metric every principal and dean tracks: graduate placements.
5.1 Who is actually hiring AI engineers - and what they pay
The agentic AI hiring market in 2025-2026 is not concentrated in a small number of elite employers. It is broad-based, well-funded, and global. Naming the categories of employers and the verifiable compensation patterns is the clearest way to make the scale of the shift visible.
Frontier AI labs are setting the upper ceiling of compensation. Public disclosures and industry reporting through 2025 establish that frontier AI research engineers at OpenAI, Anthropic, Google DeepMind, xAI, Meta, and a small set of well-funded AI startups (Mistral, Thinking Machines Lab, Cohere) command total compensation ranging from several hundred thousand dollars to over $1 million annually for senior individual contributors. Meta’s 2025 hiring push to staff Meta Superintelligence Labs included individual packages reportedly worth hundreds of millions of dollars over several years for top researchers - extreme figures that triggered counter-offers across the industry and pushed compensation higher at every tier below. These are not normal compensation patterns. They reflect a market where a handful of frontier labs are competing aggressively for a small pool of senior AI researchers. But the picture below this tier matters more for college placements.
Hyperscalers and established technology companies are hiring AI engineers at scale. General AI Engineer roles at Google, Meta, Microsoft, Amazon, Nvidia, Apple, and other large technology employers form the bulk of US AI hiring volume. Glassdoor’s February 2026 data places the US AI/ML Engineer national average at $173,482, with 90th-percentile compensation reaching approximately $269,611. These are general AI engineering roles, not frontier research positions, and they represent the realistic target market for most graduates entering AI engineering careers.
AI-first startups are hiring across all levels. Companies like Cohere, Glean, Grammarly, Harvey, Sierra, Decagon, Replit, and hundreds of others across the US, UK, Europe, and Israel compete for the same talent pool, raising compensation across the entire market. The Stanford AI Index 2026 documented 1,953 newly funded AI companies in the United States in 2025 alone, more than ten times the next closest country - each of them building AI engineering teams.
Volume of hiring has accelerated sharply. US AI-related job postings grew at strong double-digit rates year-on-year through 2024-2025, with Machine Learning Engineer postings among the fastest-growing job categories tracked. The Stanford AI Index 2026 confirms 88% organisational AI adoption globally and projects continued workforce expansion as enterprise agent deployment scales from its current single-digit baseline.
The Indian market is now a major destination for AI hiring. Two forces are driving Indian AI engineering hiring growth. The first is the global expansion of AI engineering itself - Indian engineers are being hired both by domestic AI-first startups and by global companies setting up India-based AI engineering teams. The second is cost arbitrage. An AI engineer in India with 3-5 years of experience earns approximately ₹18-35 LPA. The equivalent role in the United States costs the same global employer $150,000-$250,000 - roughly ₹1.25-2 crore annually. Global companies building AI teams are actively choosing to hire in India to access strong technical talent at a fraction of the US cost. Indian salaries remain among the highest in the domestic technology job market, even as they look modest by US comparison.
Indian compensation by AI role (drawing on NASSCOM 2025, Cambridge Infotech salary data April 2026, and BuildFastWithAI India Salary Report 2026):
Machine Learning Engineer: Fresher ₹7-14 LPA; Mid-level (3-5 years) ₹18-35 LPA; Senior ₹40-80 LPA
Generative AI Engineer / LLM Engineer (the newest role): Fresher ₹10-20 LPA (notably higher than traditional ML); Mid-level ₹20-45 LPA. Companies report struggling to find enough candidates at any experience level.
Agentic AI Engineer (emerging role): Junior ₹12-20 LPA; senior salaries reaching ₹35-80+ LPA. Most companies are promoting GenAI engineers into agentic roles rather than hiring fresh, because the talent pool does not yet exist.
5.2 The compression below: entry-level hiring is contracting for those without AI skills
While AI engineering hiring expands, entry-level hiring in adjacent areas is contracting sharply. This is the asymmetry college leadership needs to understand.
The Stanford AI Index 2026 documents the pattern with two specific findings (Top Takeaways #9):
US developers aged 22-25 saw employment fall nearly 20% from 2024 levels, even as headcount for older developers continues to grow
Productivity gains of 14-26% are concentrated in customer support and software development - the same categories where entry-level employment is now contracting
The conclusion that follows is sharp. The hiring market is bifurcating. Graduates with demonstrable AI engineering skills are in the highest-demand category in technology. Graduates with traditional CS or software engineering profiles but no AI engineering portfolio are competing in a market where AI is doing much of the work their first year of employment used to consist of. The same college may produce both kinds of graduates in the same batch.
This bifurcation is the practical implication of the Stanford AI Index’s productivity findings. When AI tools deliver 14-26% productivity gains in software development, the headcount that gets affected is overwhelmingly the junior tier - because the junior tier was doing the work that AI now does as a first pass. Senior engineers retain their roles because their work involves judgement and architectural decisions that AI does not yet handle reliably. Junior engineers without AI engineering skills face a structurally smaller market.
5.3 What recruiters are actually screening for
The clearest signal of what AI employers want is what they say publicly on their own careers pages.
Anthropic’s hiring page states explicitly that PhD and prior ML experience are not required, and that approximately 50% of their technical staff do not have PhDs. The specific line that matters for college students: “If you have done interesting independent research, written an insightful blog post, or made substantial contributions to open-source software, put that at the TOP of your resume.”
This is the most important publicly-stated hiring signal in the industry. It tells college students three things that are not yet reflected in most placement preparation:
The transcript is not the asset. Public work is. A deployed agentic system on GitHub with a written technical explanation beats a top-decile CGPA at most AI-first companies in 2026.
Portfolio evidence is screened explicitly, not implicitly. The interviewer is going to ask about it. The student who has nothing to show signals that their AI exposure was theoretical.
The path is not gated by graduate-level credentials. Independent research, open-source contributions, and substantive technical writing carry equal or greater weight than formal degrees.
Conversations with hiring managers at AI-first companies in 2025-2026 reveal consistent additional patterns:
Recruiters are screening for judgement, not just knowledge. The ability to recognise when an AI output is wrong, when a workflow needs human review, when a tool has been mis-applied. This is what employers mean by “AI fluency at the seam between AI and human work.”
Recruiters are screening for process-level thinking, not just individual productivity. The ability to look at a business workflow and identify where AI can be inserted, where it should not be, and how the workflow should be redesigned around it. A graduate who can use ChatGPT to write better emails is at the individual level. A graduate who can look at a customer support process and say “steps one through three should be agent-handled, step four needs human review, step five can auto-route” is operating at the process level. The second graduate is doing what a year-three junior consultant used to do.
Recruiters are asking about failure modes, not just success cases. Interviewers in AI engineering roles now routinely ask: “Tell me about a time your AI implementation failed. What did you learn?” Students who can answer this with specificity have built something. Students who cannot are signalling that their AI exposure was theoretical.
Hidden roles matter. A particularly important pattern in current AI hiring: many AI engineering hires do not have “AI” in their job title. Companies routinely hire engineers as backend engineers, infrastructure engineers, or platform engineers who in practice spend much of their time building AI agent workflows, RAG pipelines, evaluation systems, and production deployment for AI features. Title-based screening misses them. This means the colleges that produce strong general engineering graduates with embedded AI skills - rather than narrow AI/ML specialists - may be supplying a larger market than the job titles suggest.
5.4 The quiet placement filter
The hiring market signals above translate into a specific pattern that is now visible across Indian colleges in 2025-2026 placement seasons - though the pattern is not always announced by recruiters.
Recruiter targets are concentrating into a smaller list of colleges. The total number of campus visits per recruiter has remained roughly stable; the colleges that receive offers are clustering. Recruiters do not tell placement officers directly that their college has been deprioritised. The information emerges later, when the next campus season produces fewer offers without explanation.
Pre-placement talks now include questions that did not exist three years ago. Recruiters are asking placement coordinators: “How does your curriculum integrate AI tools across coursework? Do students have portfolio projects involving foundation models? Can students discuss production tradeoffs?” The principal or HoD who cannot answer these crisply loses recruiter confidence. The loss does not show in current-year numbers - it shows up two cycles later.
Median placements may hold while top-quartile placements flatten first. This is the most subtle pattern. The students who would have received the best offers - top-percentile candidates from second-tier colleges - are increasingly being out-competed by candidates from less prestigious institutions who demonstrate AI-augmented work in interviews. The college’s median holds; its ceiling drops.
The cost of waiting is asymmetric. Colleges that adapt now can absorb agentic engineering into existing AI/ML programmes within 12-18 months. Colleges that wait one or two placement cycles will face a harder problem: recovering recruiter confidence after a visible placement decline, while simultaneously rebuilding curriculum and retraining faculty. The first scenario is a curriculum project. The second is a brand recovery project.
6. Common responses that fail
Five common reflexive responses to this kind of analysis are visible across colleges in 2025-2026. Each of them is well-intentioned. Each of them fails to close the gap.
Adding a one-semester AI elective. This is the most common response and the least effective. Agentic fluency is not a topic - it is a way of working. A single elective does not change how students approach their final-year projects, their summer internships, or their case interviews. Recruiters are not looking for a transcript line showing “AI elective completed.” They are looking for evidence that students think with AI across their work.
Teaching agentic AI as theory. Colleges with strong faculty in computer science or statistics will be tempted to teach the foundations of large language models, transformer architectures, optimisation theory underlying agent loops. This is valuable for the 5% of students who will become AI researchers. It is the wrong training for the 95% who will work alongside AI as employees. The latter need fluency at the seam, not the system underneath.
Outsourcing to a vendor without integrating it. Colleges that recognise the urgency often bring in an external trainer for a workshop or short course. This is better than nothing. But the students who attend learn a tool; the students who do not attend - often the ones who would have benefited most - remain in the unfiltered pool. And the faculty, who do not use AI themselves, cannot reinforce the fluency in their own courses. The skill does not become institutional.
Teaching only individual productivity, not process-level thinking. Even colleges that take the issue seriously usually stop at the first competency: how to use AI to draft emails, summarise documents, write code. Graduates trained only on individual productivity will compete for second-draft roles - the entry-level work that is increasingly being automated. Graduates trained on both individual productivity and process-level workflow redesign will compete for the work companies cannot currently find anyone to do.
Treating it as a placement-time fix. The most dangerous response is to do nothing for three years and then run a crash course on AI tools before placement season. Judgement at the seam between AI and human work is built through 18 months of using AI in actual coursework - making mistakes with it, catching its errors, building intuition. It cannot be retrofitted in four weeks.
7. What augmentation could look like
The framing of this brief has been “augmentation, not replacement.” This is genuine. Strong AI/ML and Data Science curricula are valuable foundations. The question is what gets layered on top.
Three levels of augmentation are worth considering, by ambition and institutional readiness:
Level 1: Awareness layer (1-2 sessions per cohort). A focused exposure for faculty and students on what agentic AI engineering is, what tools exist, what hiring is currently looking for, and what students should be doing on their own to build a portfolio. This is not a curriculum change - it closes the literacy gap so that students can take the next step independently and faculty can answer student questions credibly.
Level 2: Practical layer (2-day workshop to 4-week structured course). A hands-on programme where students build a working agentic system end-to-end - design, implementation, deployment, evaluation. The output is a portfolio piece each student can show to recruiters, and a reference implementation faculty can use as a teaching template. This sits alongside existing AI/ML curriculum without disrupting it.
Level 3: Structured curriculum integration (semester or year-long). Integration of agentic engineering as a formal module within existing AI/ML or CSE programmes. Capstone projects assessed on agentic engineering quality. Requires faculty co-development and a longer institutional commitment.
The right starting point for most institutions is Level 1 or Level 2, depending on institutional readiness and the appetite of the department for change. Level 3 typically follows after a successful Level 2 deployment that produces visible student outcomes.
A few practical principles distinguish augmentation that succeeds from augmentation that fails:
Faculty must be trained alongside students. If only students are trained, the skill does not become institutional and the curriculum cannot evolve to reinforce it.
Real production tools must be used. Foundation model APIs (Claude, OpenAI, Gemini), real deployment platforms, actual production code. Toy projects do not transfer.
Students must publish their work. Public GitHub repositories, deployed URLs, written technical explanations. Portfolio evidence is what recruiters now screen on.
The curriculum must update continuously. Foundation model capabilities change every 6-12 months. Vendor-specific tutorials become obsolete fast. Engineering judgement is what transfers.
In choosing a partner for any level of augmentation - whether internal, external, or hybrid - the questions that distinguish strong partners from weak ones are:
Does the partner build agentic systems hands-on, with working code, or do they only teach concepts? Look for technical content, working demonstrations, published technical writing, open-source artefacts. Engineering depth is observable.
Is the curriculum mapped to a defined progression, or is it a loose collection of topics? A structured framework that takes students from foundations to advanced capability is essential for serious institutional engagement.
Will they train faculty alongside students, or only students? Without faculty enablement, the skill does not become institutional and the curriculum cannot evolve.
Is the curriculum tied to the current frontier, or is it frozen at 2023 capabilities? Foundation models change rapidly; any partner whose curriculum has not updated in the last 6 months is teaching outdated material.
Do they bring real industry context, from people who have worked at frontier AI companies or in production technology environments? AI agentic engineering is industry curriculum first; it is taught well only by people who have lived in the relevant industry context.
The most important test is not the partner’s specific deployment history - it is whether the partner thinks deeply about the work and can teach it credibly. Engineering judgement transfers; vendor-specific tutorials do not.
8. Closing
The shift in the AI hiring market is not a forecast. It is happening now, documented in primary research from Stanford’s AI Index 2026, LinkedIn’s Skills on the Rise 2026, McKinsey, PwC, and multiple credible labour market analyses. The shift is visible in global hiring data and Indian context. It is visible in enterprise adoption surveys. It is visible in government deployments at national scale. It is visible in the structural compression of Indian IT services fresher hiring from 600,000 in FY22 to 120,000 in FY25.
What is also visible, in the patterns of campus placement data and recruiter behaviour, is that the colleges that produce graduates capable of building agentic systems on frontier models will define their placement reputation for the next decade. The colleges that wait will spend the next decade explaining why their placement numbers quietly declined while their better-prepared peers absorbed the new hiring demand.
This is not an argument that traditional AI/ML and Data Science curricula were wrong. They were correct for the era in which they were designed. The argument is that the era has shifted, the evidence is now overwhelming, and the cost of acting in the next 12-18 months is meaningfully lower than the cost of acting in three years.
College leadership in 2026 has an opportunity that may not exist again in the same form. The foundation has been built. The augmentation required is incremental, not revolutionary. The students currently in their second or third year still have time to graduate with the skill stack the market is now asking for. The decision is whether to act on that opportunity now or to wait for the placement data to make the decision unavoidable.
Sources cited
Stanford Institute for Human-Centered AI (HAI), AI Index Report 2026, April 2026. Available at: https://hai.stanford.edu/assets/files/ai_index_report_2026.pdf
LinkedIn Economic Graph, Skills on the Rise 2026, February 24, 2026. Available at: https://www.linkedin.com/pulse/linkedin-skills-rise-2026-fastest-growing-us-linkedin-news-nujwe/
McKinsey & Company, The State of AI 2025, March 2025. Available at: mckinsey.com
PwC, AI Agent Survey, May 2025. Available at: pwc.com
Anthropic public hiring page (cited for portfolio-over-credentials statement); available at: anthropic.com/careers
Glassdoor, February 2026 (US AI/ML Engineer national average compensation data)
NASSCOM 2025, Cambridge Infotech salary data April 2026, BuildFastWithAI India Salary Report 2026 (cited for Indian AI engineering compensation ranges)
OpenAI customer story for Klarna deployment 2024; Fast Company January 2026; Business Insider 2025 (cited for Klarna AI customer service story and walk-back)
Multiple industry reports tracking Indian IT services fresher hiring (Business Today, Economic Times), 2025-2026
Public company case studies and 2025 deployment announcements from Salesforce, Oracle, Microsoft, SAP, Amazon, ServiceNow, Thomson Reuters, eSentire, L’Oreal, Wyndham
UAE federal government announcement on autonomous agentic AI deployment framework, April 2025
Singapore GovTech and Smart Nation 2.0 strategy documentation, 2024-2025
Prabhu Eshwarla is the founder of GradTensor, a Bengaluru-based AI education and engineering boutique providing AI agentic engineering training to colleges, technical training institutions, and corporates. He has a master’s degree in Engineering from BITS Pilani, 25+ years in technology across global clients in financial services, manufacturing, telecom, and consulting, and is the author of two technical books on systems and backend engineering (Manning, 2022; Packt, 2020). He writes on AI and its institutional implications at Trust and Reason. He can be reached at prabhu@gradtensor.com.